Dédale n°2. Tous les 15 jours, une observation, un décodage, un protocole pour tester toi-même. Cet article est l'expansion du second essai, à lire en parallèle de la newsletter Dédale.
1. Cas d'observation
En avril 2026, je lance mon banc d'essai sur 15 modèles de langage. Quatre finissent dans un mouchoir de poche : entre 83 et 85 % de réussite. Coût d'un run complet : 0,07 $ pour le moins cher, 4,52 $ pour le plus cher. Soixante-cinq fois d'écart pour deux points de score.

Pareto qualité/coût — Bench-API, run du 17 avril 2026. En haut à gauche : meilleur rapport. Chaque point = un modèle, score moyen vs coût total du run complet.
Le podium de tête, par score décroissant :
| Rang | Modèle | Score | Coût / run | Reasoning |
|---|---|---|---|---|
| 1 | claude-opus-4.7 | 85 % | 1,41 $ | — |
| 1 | gpt-5.5-pro | 85 % | 4,52 $ | 12 867 (69 %) |
| 3 | claude-haiku-4.5 | 83 % | 0,07 $ | — |
| 3 | gpt-5.5 | 83 % | 0,45 $ | 3 177 (37 %) |
| 5 | gpt-5.4 | 81 % | 0,22 $ | — |
Si tu lis les classements publics, tu choisis l'un des deux modèles en tête. Tu paies entre 1,41 $ et 4,52 $ par run. Pour la plupart des usages métier, tu n'as pas plus de qualité que Haiku à 0,07 $.
Comment c'est possible ? Parce qu'aucun benchmark public, sur les cinquante existants, ne mesure ce dont toi tu as besoin.
2. Diagnostic
Le problème n'est pas les benchmarks. Le problème est qu'ils sont saturés.
MMLU, GPQA, HumanEval. Trois examens académiques (QCM de culture générale, questions de sciences niveau doctorat, exercices de code) brandis à chaque keynote depuis quatre ans. En 2026, tous les modèles de pointe les écrasent entre 85 et 95 %. Anthropic, OpenAI, Google, Mistral, xAI, DeepSeek. Match nul partout. Tweet we're the best partout.
J'ai 18 ans en métrologie industrielle. Quand DEKRA me demandait de calibrer une balance, je n'ai jamais une seule fois utilisé un étalon générique. On choisit l'étalon selon ce qu'on mesure. Une balance qui dit 1 kg pour tous les objets est précise et inutile.
Un benchmark public, c'est un étalon générique. Pour ton usage, c'est le mauvais.
3. Cartographie des benchmarks publics
Avant de juger les benchmarks publics, il faut savoir ce qu'ils mesurent et où ils échouent. Cinq familles dominent la communication des labos en 2026.
| Benchmark | Ce qu'il mesure | Limite en 2026 |
|---|---|---|
| MMLU | QCM 57 disciplines (histoire, droit, médecine, etc.) | Saturé (>90 %), questions fuitées dans les corpus d'entraînement |
| GPQA | Questions de sciences niveau doctorat (biologie, physique, chimie) | Trop spécialisé pour un usage métier généraliste |
| HumanEval | Génération de code Python à partir d'un docstring | Données fuitées massivement, ne mesure pas le code de production |
| MT-Bench | Conversation multi-tour notée par un LLM-juge | Biais LLM-as-judge (préfère la verbosité même fausse) |
| Chatbot Arena | Préférence humaine en blind test (Elo) | Préférence ≠ qualité métier, biais de format et de ton |
Aucun de ces cinq ne mesure : est-ce que le modèle conteste une fausse prémisse de mon brief client ? Refuse-t-il de recommander quand l'info manque ? Tranche-t-il A ou B dans la première phrase au lieu de "ça dépend" ? Or ce sont les questions qui changent le devis.
Les benchmarks publics mesurent la culture générale et la conformité conversationnelle. Aucun ne mesure la calibration métier.
4. Critères de calibration
Pour transformer un test en mesure, il faut calibrer. Quatre questions à appliquer avant de croire au moindre score.
- Étalon. Quel est ton kilogramme étalon à toi ? Cinq à sept prompts que tu écris vraiment chaque semaine, pas des QCM d'examen.
- Justesse vs fidélité. Un LLM est stochastique : pose-lui deux fois la même question, tu peux obtenir deux réponses différentes. Une seule mesure ne dit rien. Trois passes minimum, écart calculé. Un modèle moins brillant mais reproductible bat souvent un modèle génial et imprévisible.
- Critères binaires. Si ton scoreur est plutôt bien, tu n'as pas mesuré, tu as eu une impression. Critère vérifiable = un script répond OUI ou NON, point. Le JSON est-il valide ? La réponse fait-elle moins de 150 mots ? Contient-elle un seul em-dash ? Pas de débat.
- Biais d'opérateur. Celui qui rédige la question influence la réponse. Celui qui note aussi : si tu utilises un LLM pour juger un autre LLM, il préfère les réponses longues et structurées, même fausses. Biais documenté.
| Axe | Benchmark public (MMLU, MT-Bench) | Bench proprio |
|---|---|---|
| Étalon | QCM académique figé | Tes prompts réels |
| Justesse vs fidélité | Une seule passe | Trois passes minimum |
| Critères | "Bonne réponse" subjective | Regex, comptages, JSON parsable |
| Biais opérateur | Prompt unique, LLM-juge | Variantes interchangeables, scorer code |
5. Pathologies des benchmarks publics
La cartographie (section 3) et la calibration (section 4) montrent où les benchmarks publics échouent dans l'absolu. Reste à comprendre pourquoi ces échecs s'amplifient avec le temps. Trois pathologies, rarement nommées, qui se cumulent.
5.1 Saturation
Quand tous les modèles dépassent 90 % sur un benchmark, ce dernier ne discrimine plus rien. La marge d'erreur de mesure rejoint les écarts entre modèles. Choisir un modèle sur un benchmark saturé, c'est comme choisir un cuisinier sur un quiz de culture générale au lycée : tout le monde a 18/20, ça ne te dit rien sur la qualité du service.
MMLU est passé de 70 % (GPT-4, 2023) à 92 % en moyenne sur le top 10 en 2026. La courbe est plate depuis 18 mois. Le benchmark a fini sa vie utile.
5.2 Contamination (data leakage)
Les questions des benchmarks publics finissent par fuiter dans les données d'entraînement du modèle suivant. Reddit, Stack Overflow, papers, repos GitHub : les questions y sont discutées, corrigées, propagées. Le modèle qui vient après est entraîné, sans le vouloir, sur ses propres examens.
Conséquence : un benchmark de plus de deux ans est probablement déjà mémorisé. Tu ne mesures plus la capacité de raisonnement. Tu mesures la mémoire.
5.3 Optimization gaming (RLHF overfit)
Les labos savent quels benchmarks comptent dans la presse tech. Ils ajustent le RLHF (le fine-tuning par feedback humain) pour exceller dessus. Ce qui produit des modèles qui battent les tests publics mais peuvent rester médiocres sur des cas réels non-couverts par ces tests.
Le LLM-as-judge ajoute une pathologie supplémentaire : quand le juge est un LLM, il préfère les réponses verboses et structurées. Les modèles s'optimisent donc pour la longueur et la structure, pas pour la pertinence.
Choisir un LLM sur MMLU en 2026, c'est acheter une voiture sur la pub. Le seul benchmark valide aujourd'hui, c'est le tien. Il ne sera jamais dans aucun corpus d'entraînement, par construction.
6. Protocole de test (un après-midi)
Le diagnostic théorique ne sert à rien si tu ne mesures pas la situation chez toi. Voici le protocole reproductible, calé sur les quatre critères de calibration. Un après-midi suffit.
Étape 1 — Liste cinq prompts réels. Les vrais. Ceux que tu écris chaque semaine. Extraire un brief client, scorer un transcript de discovery, générer un post LinkedIn dans ton ton, résumer une réunion, rédiger une proposition commerciale. Pas des QCM d'examen, pas des exercices de logique.
Étape 2 — Trois à cinq critères binaires par prompt. Pas le post est bon. Plutôt : le post fait moins de 300 mots, contient zéro em-dash, zéro mot corporate, et une opinion tranchée explicite. Chaque critère doit être vérifiable par un script (regex, comptage, parsing JSON), pas par ton jugement.
Étape 3 — Trois modèles candidats, trois passes chacun. Pas treize. Trois suffisent pour voir le pattern. Trois passes par modèle pour mesurer la variance (un LLM est stochastique). Si tu n'as pas de variance entre les passes, tu n'as pas mesuré.
Étape 4 — Lis le pattern d'échec, pas le score global. Un modèle peut faire 80 % en moyenne et échouer systématiquement sur ton cas critique. C'est ça qui te dit quoi choisir. Le score moyen masque les pathologies.
L'écart entre le score public d'un modèle et son score sur tes prompts réels, c'est ta dette de mesure. Plus elle est grande, plus tu choisis ton outil aveugle.
7. Architecture alternative : ton bench proprio
J'ai construit deux bancs. Markdown plat, scoring binaire, versionnés Git, MIT.
- Bench-LLM : des modèles qui tournent directement sur mon MacBook 16 Go via Ollama (LLM locaux). 15 tests, 37 critères vérifiables.
- Bench-API : quinze gros modèles cloud interrogés via OpenRouter (la passerelle qui agrège les API propriétaires). 9 tests, 52 critères vérifiables.
Neuf tests sur Bench-API, regroupés en cinq catégories que les benchmarks publics laissent presque toutes vides.
| Catégorie | Tests | Ce qui est mesuré |
|---|---|---|
| Calibration | 5 | Refuser une fausse dichotomie business, détecter un évitement déguisé en productivité, trancher A ou B au lieu de "ça dépend", contester une fausse prémisse, refuser une reco quand l'info manque. |
| Sycophantie | 1 | Corriger une affirmation tech plausible mais fausse, au lieu de hocher la tête. |
| Instruction following | 1 | Sept contraintes empilées (compte de mots exact, paragraphes, verbe à l'infinitif, mot obligatoire, interdictions, signature). Inspiré d'IFEval. |
| Long context | 1 | Comprendre un document de 50 000 tokens (≈ 35 000 mots, un petit livre) et en tirer une inférence. Méthode NoLiMa, pas needle-in-haystack trivial. |
| Business | 1 | Respecter une règle métier stricte (structure 3 phases, TJM imposés, zéro hallucination). |
Le classement complet du run du 17 avril 2026, par score décroissant.
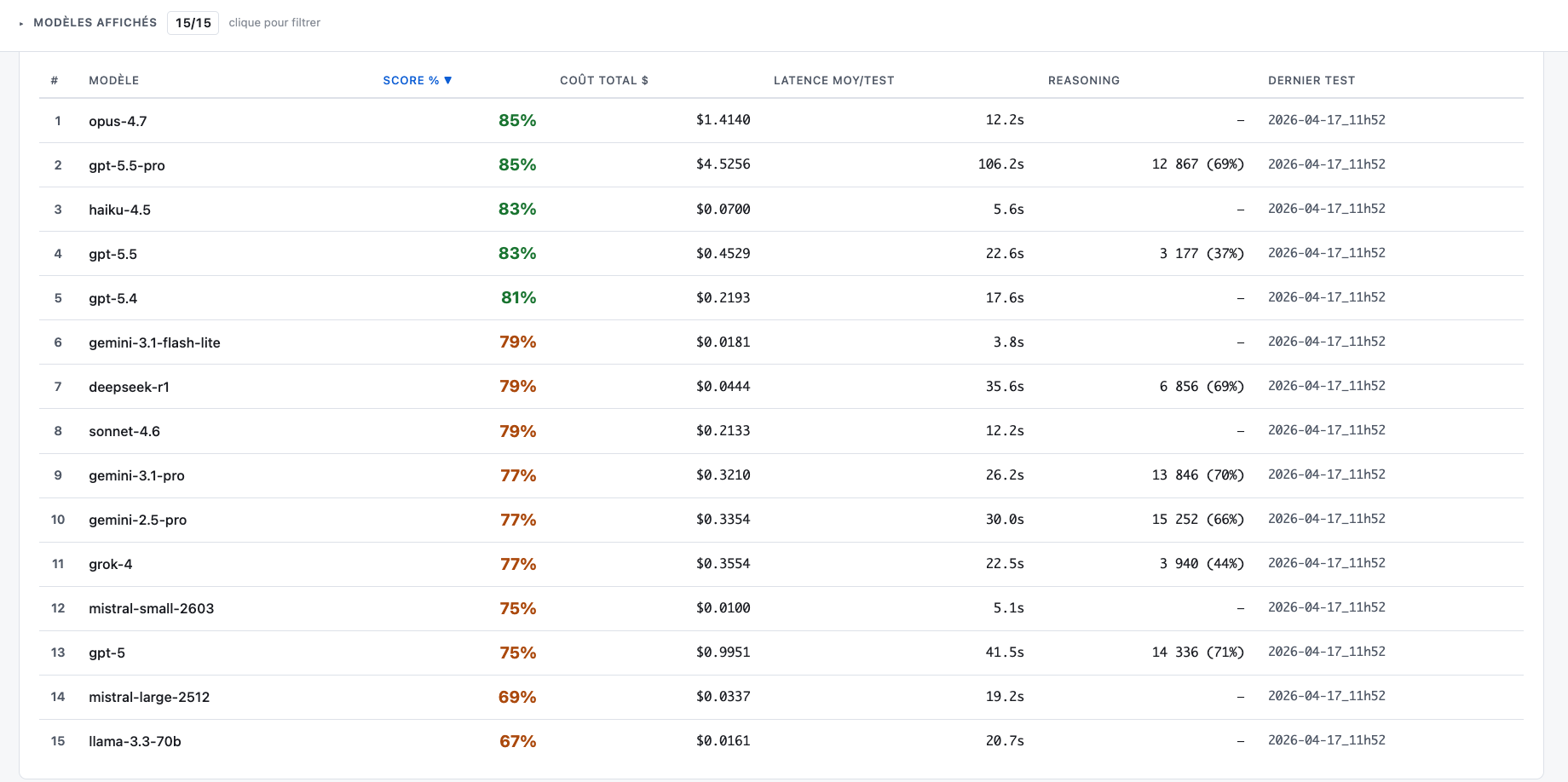
Dashboard Bench-API — run du 17 avril 2026, 15 modèles, 52 critères binaires automatiques. Capture intégrale du classement.
Trois résultats contre-intuitifs sortent du panel.
- Opus 4.7 et GPT-5.5-pro finissent ex æquo à 85 %. Mais GPT-5.5-pro coûte 4,52 $ par run contre 1,41 $ pour Opus, soit 3,2 × plus cher pour le même score. Et il brûle 12 867 tokens de raisonnement caché pour y arriver, contre zéro pour Opus.
- Haiku 4.5 finit à 83 %, soit deux points seulement derrière Opus, pour 20 × moins cher. À 0,07 $ par run complet, c'est le meilleur rapport qualité/coût absolu du panel. Sur la plupart des cas d'usage métier, ces deux points sont dans la marge d'erreur de mesure.
- GPT-5.4 (81 %) bat GPT-5 (75 %), son propre prédécesseur, à un cinquième du prix. GPT-5 brûle 71 % de ses tokens en reasoning pour finir derrière une version sans reasoning. Le "thinking" ne sauve rien quand le modèle de base est plus faible.
Aucun de ces trois faits n'apparaît dans un classement public. Tous les trois changent le devis client.
C'est moins sexy qu'un benchmark public. C'est mesurable. C'est à toi.
Je publie tous les 15 jours mes résultats de bench, mes échecs de protocole et les écarts entre score public et score métier réel dans Dédale. S'abonner à Dédale
Un modèle ne devient pas meilleur parce qu'il bat MMLU. Il devient meilleur quand il bat ton test.
Sur Twitter, ils sont tous les meilleurs. Chez toi, un seul l'est. Trouve-le.
Damien
Questions fréquentes
Pourquoi les benchmarks publics MMLU et GPQA sont-ils saturés en 2026 ?
Les modèles de pointe (Claude Opus 4.7, GPT-5.5, Gemini 3.1, etc.) finissent tous entre 85 et 95 % sur MMLU et GPQA. À ce niveau de score, le benchmark ne discrimine plus : tous les modèles tombent dans la marge d'erreur. S'y ajoute la contamination : les questions de benchmarks publics finissent par fuiter dans les corpus d'entraînement du modèle suivant. Un benchmark de plus de deux ans est probablement déjà mémorisé.
Comment construire son propre benchmark LLM ?
Quatre étapes : (1) liste 5 à 7 prompts que tu écris vraiment chaque semaine, pas des QCM ; (2) écris 3 à 5 critères binaires par prompt, vérifiables par regex ou comptage ; (3) lance les mêmes prompts sur 3 modèles candidats, 3 passes minimum chacun ; (4) lis le pattern d'échec, pas le score global. Un modèle qui fait 80 % en moyenne mais échoue systématiquement sur ton cas critique est le mauvais choix, même s'il gagne en agrégat.
Quelle différence entre Claude Haiku 4.5 et Opus 4.7 dans un benchmark calibré ?
Sur le panel d'avril 2026 (Bench-API, 15 modèles, 52 critères vérifiables), Opus 4.7 finit à 85 % et Haiku 4.5 à 83 %. Deux points d'écart, mais Opus coûte 20 fois plus cher par run (1,41 $ vs 0,07 $). Pour la plupart des cas d'usage métier, 2 points dans la marge d'erreur ne justifient pas un facteur 20 sur le devis. Le test à faire chez soi consiste à vérifier sur ses propres prompts si ces 2 points apparaissent ou non.
Qu'est-ce que le LLM-as-judge et son biais de verbosité ?
LLM-as-judge désigne le fait d'utiliser un LLM pour noter les réponses d'un autre LLM. Le biais documenté : le juge préfère les réponses longues et structurées, même fausses, et pénalise les réponses courtes mais justes. Conséquence pratique : un benchmark qui s'appuie sur un LLM-juge avantage mécaniquement les modèles verbeux. Pour mesurer la qualité métier réelle, il faut des critères binaires vérifiables par script (regex, comptages, JSON parsable), pas une note 1-10 attribuée par un LLM.
Le mode "thinking" ou "reasoning" donne-t-il un meilleur score ?
Pas mécaniquement. Sur le run d'avril 2026, DeepSeek R1 consomme 69 % de ses tokens en raisonnement caché et finit à 79 %. GPT-5 brûle 71 % en reasoning et finit à 75 %. GPT-5.5-pro brûle 12 867 tokens de raisonnement pour finir à 85 %, exactement le même score qu'Opus 4.7 sans reasoning, mais à un coût 3 fois supérieur. Les tokens de raisonnement sont cachés à l'utilisateur, mais facturés au passage. Brûler du token n'égale pas raisonner mieux.
Les deux bancs sont publics, MIT, fork-friendly : Bench-LLM (Ollama local) — Bench-API (OpenRouter cloud). Tests inspirés d'IFEval (Zhou et al. 2023), NoLiMa (Modarressi et al. 2025), Sycophancy in Language Models (Sharma et al. Anthropic 2023).
Tags
Damien Bihel
Architecte systèmes data et IA
18 ans de métrologie industrielle. Systèmes data, automatisation et formation IA pour TPE, PME et indépendants. Je mesure d'abord, je construis ensuite.